Hugging Face の音声テキスト変換モデルのおかげで、音声をテキストに変換するのがかつてないほど簡単になりました。インタビューの文字起こし、字幕の生成、AI を活用したアプリケーションの開発など、Hugging Face は高度な機械学習モデルを活用した最先端の音声認識を提供します。一番いいところは?高度にカスタマイズ可能なため、特定のニーズに基づいてモデルを微調整して精度とパフォーマンスを向上させることができます。
このガイドでは、音声合成 Hugging Face API の設定と使用方法を説明します。 、カスタマイズ オプションを検討し、実際の使用例について説明します。しかし、もっと簡単な代替手段が必要な場合はどうすればよいでしょうか?心配しないでください。作業を簡単に完了できる、使いやすい音声テキスト変換ツールも紹介します。デベロッパー、コンテンツ クリエイター、ビジネス プロフェッショナルのいずれであっても、このガイドはワークフローに最適な音声テキスト変換ソリューションを見つけるのに役立ちます。読み続けてください。
この記事について
<オル>パート 1:ハグ顔でのスピーチをテキストに変換する仕組み
Hugging Face Speech-to-Text は、Hugging Face Transformers ライブラリ内の優れた機能で、事前トレーニングされたモデルを使用して話し言葉を書き言葉に変換できます。高度な自動音声認識 (ASR) テクノロジーを使用して音声を書き起こします。 Wav2Vec2 のようなトランスフォーマー ベースのアーキテクチャを使用すると、システムはオーディオ データを処理してテキストに変換します。そしてそれは非常に正確に行われます。
顔を抱きしめながら音声をテキストに変換できる機能の 1 つ 際立っているのは、開発者にとって非常に簡単になるパイプライン統合です。わずか数行のコードで、オーディオ ファイルを処理し、テキストのトランスクリプトを取得できます。また、複数の言語と音声シナリオ用に事前トレーニングされたモデルがあるため、多くのユースケースに適応できます。
音声をテキストに変換するプロセスは、正確な文字起こしを保証するために、ステップバイステップのシーケンスに従います。
- 音声入力:処理する音声ファイルを提供します。
- 特徴抽出:システムは音声特徴、ログメル フィルター バンクを抽出します。これは音声パターンの分析に役立ちます。
- モデル推論:事前トレーニングされたトランスフォーマー モデルが特徴を処理し、話し言葉を表すテキスト トークンを生成します。
- テキスト出力:モデルはこれらのトークンをテキストのトランスクリプトに変換します。
Hugging Face の音声テキスト変換モデル、特に SeamlessM4T-v2 は、デュアル シーケンスツーシーケンス (seq2seq) フレームワークを実装することで効率を向上させます。個別の音声エンコーダーとテキスト エンコーダー、および生成される音声の品質を向上させる HiFi-GAN ボコーダーを備えています。これは、仮想アシスタント、ライブ キャプション、文字起こしサービス、音声検索などのアプリケーションを備えた、音声認識と自動化に役立つツールです。
パート 2:ハグ顔音声をテキストに変換する設定
以下は、ハグ顔音声読み上げを使用するためのセットアップ方法に関するステップバイステップのガイドです。
ステップ 1:ハグフェイス アカウントを作成する

まず必要なのは、Hugging Face のアカウントです。アカウントを作成すると、事前トレーニングされたモデルと API にアクセスできるようになります。まだアカウントをお持ちでない場合は、
- ハグフェイスのウェブサイトにアクセス
- 「サインアップ」をクリックします
- 詳細を入力してアカウントを作成します
- ログインしたら、プロフィール設定に移動します
- アクセス トークンを見つけて、新しいトークンを作成します (権限レベルとして「書き込み」を選択します)
このトークンは、コードから Hugging Face に接続するのに役立ちます。
ステップ 2:必要なライブラリをインストールする
次に行う必要があるのは、必要なライブラリをすべてインストールすることです。これを行うには、ターミナルまたはコマンド プロンプトを開いて次のように入力します。
pip インストール トランスフォーマー データセット torchaudio librosa サウンドファイル
Transformers は Hugging Face モデルをロードするために使用され、torchaudio はオーディオ データの処理に使用され、librosa と soundfile はオーディオ ファイルのロードと変更に使用されます。
ステップ 3:モデルをロードする
必要なライブラリをすべてインストールしたら、次に行う必要があるのは、音声テキスト変換モデルをロードすることです。 Wav2Vec2 は音声認識に最適な事前トレーニング済みモデルの 1 つであるため、使用できます。
トランスフォーマーからのインポート Wav2Vec2ForCTC、Wav2Vec2Processor
トーチをインポート
# モデルとプロセッサをロードします
model_name ="facebook/wav2vec2-large-960h"
プロセッサ =Wav2Vec2Processor.from_pretrained(model_name)
モデル =Wav2Vec2ForCTC.from_pretrained(model_name)
ステップ 4:音声をテキストに変換する
モデルが理解できるように音声ファイルを準備する必要があります。これを実現するには、ソフトウェアにオーディオをロードする必要があります。次に、モデルが適切に処理できるように、正しい形式であることを確認します。これをモデルで実行して、音声をテキストに変換します。
リブロサをインポート
#オーディオ ファイルをロードして 16kHz に変換します
defload_audio(file_path):
オーディオ、sr =librosa.load(file_path, sr=16000)
音声を返す
audio_file ="example.wav"
audio_input =load_audio(audio_file)
モデルが読み取れるように音声入力を処理します
input_values =プロセッサ(audio_input、return_tensors="pt"、sampling_rate=16000).input_values

注:大規模なプロジェクトの場合、Hugging Face は、自分のデバイスでモデルを管理せずに音声をリモートで処理できる API エンドポイントを提供します。 Hugging Face アカウントにサインアップし、API キーを取得し、簡単な API リクエストを介してオーディオ ファイルを送信するだけです。
Speech-to-Text モデルをカスタマイズする方法
音声からテキストへのハグ顔モデルをより適切に機能させたい場合は、微調整する必要があります。基本モデルは優れていますが、特定のアクセント、背景雑音、または特殊な単語を理解できない可能性があります。独自のデータを使用してトレーニングすると、学習と改善が促進され、ニーズをより正確に満たすことができます。モデルを微調整する方法は次のとおりです。
- カスタム データによる微調整:独自の音声データセットと文字起こしデータセットを使用してモデルをトレーニングし、特定のアクセントや業界用語の認識を向上させます。
- 推論設定の調整:温度やビーム検索などのパラメータを変更して精度を調整します。
- カスタム語彙の追加:モデルにドメインに関連する新しい単語やフレーズを教えます。
カスタマイズにより、モデルは特定のニーズに合わせてより正確で信頼性の高いものになります。ただし、より単純なソリューションを希望する場合は、音声テキスト変換の簡単な代替手段について次のセクションを確認してください。
パート 3:より簡単な代替手段:Filmora を使用した自動音声テキスト変換
ハグフェイス Speech-to-Text は複雑すぎるようで、コーディングなどの技術スキルが必要です。しかし、より簡単な代替手段があります。Wondershare Filmora は、音声をテキストに変換するはるかに簡単なアプローチです。 Filmora は、数回クリックするだけで音声を自動的に文字起こしする音声テキスト変換ツールを備えた人気のビデオ編集ソフトウェアです。
- Filmora はすべてを簡素化します。したがって、プログラミング スキルや複雑な構成は必要ありません。
- ビデオ音声を最大 99% の精度でテキストに変換できます。そのため、コンテンツ作成者、学生、さらにはビジネスプロフェッショナルも、これを使用して音声からテキストを迅速かつ正確に生成できます。
- 45 以上の言語をサポートし、ビデオの字幕、音声メモ、インタビューに適しています。
- 多言語コンテンツの自動字幕翻訳機能を搭載
- カスタマイズ可能なアニメーション キャプションを生成してエンゲージメントを高めることができます
- また、Filmora に組み込まれた音声テキスト変換機能は音声データを非常に高速に処理し、ユーザーの時間を節約します。速度と時間を節約できるため、最良の選択肢となります。
パート 4:Filmora Speech-to-Text の使用方法
Filmora を使用すると、音声をテキストに変換することが非常に簡単になります。コードを作成したり、難しい設定をしたりする必要はありません。
以下の簡単な手順に従うだけで、デスクトップの音声テキスト変換機能を使用してトランスクリプトをすぐに取得できます。
ステップ 1:オーディオまたはビデオをインポートする
Filmora を開き、オーディオ ファイルまたはビデオ ファイルを追加します。これは、タイムラインにドラッグ アンド ドロップするだけで実行できます。これにより、作業が簡単になります。ファイルが配置されたら、次に進む準備は完了です。
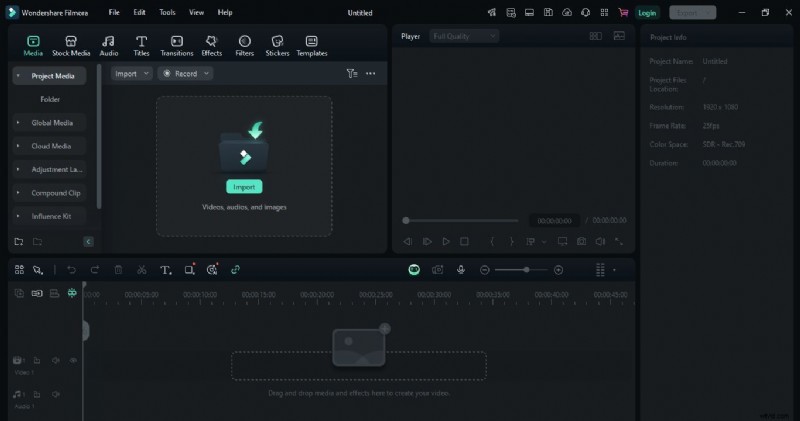
ステップ 2:Speech-to-Text オプションを選択します
上部のメニューバーの「ツール」に移動し、それをクリックします。 [音声]、[テキスト読み上げ] オプションを選択して、音声を自動的に分析します。すべてを自動的に処理してくれるため、設定を調整したり、特別なことをする必要はありません。
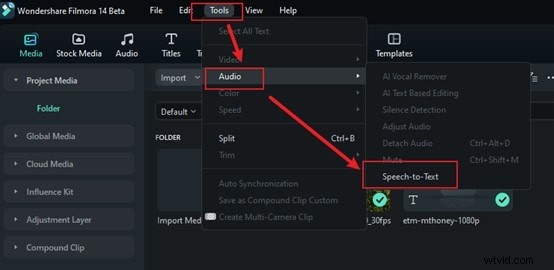
ステップ 3:言語を選択してください
Filmora は多くの言語をサポートしているため、オーディオに合った言語を選択してください。適切な言語を選択すると、Filmora が音声を正確に文字に起こすのに役立つため、この手順は重要です。これをスキップすると、誤った結果が得られる可能性があります。
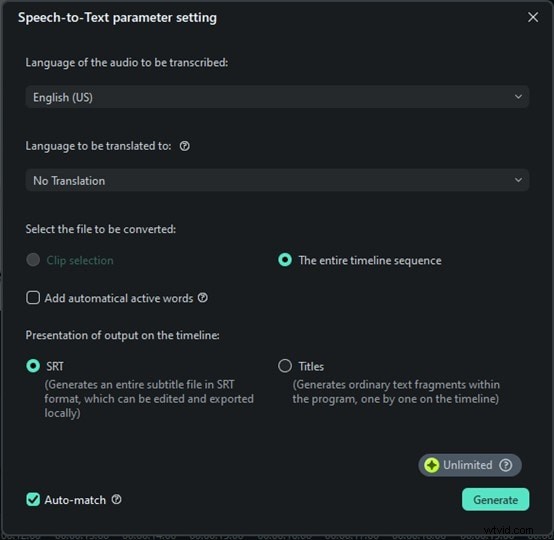
ステップ 4:文字起こしを開始して保存
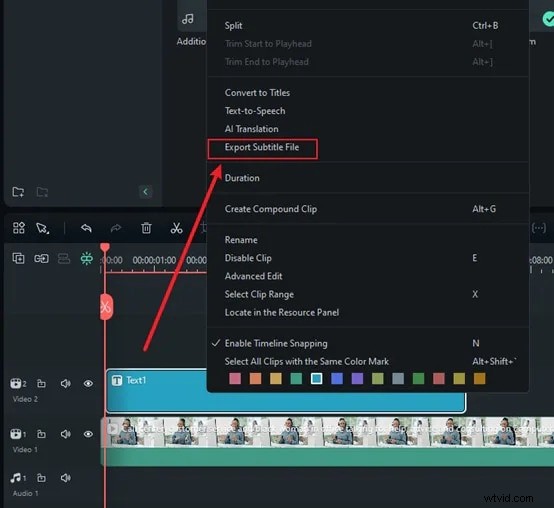
ここで、「生成」をクリックするだけで、Filmora がスピーチの文字起こしを開始します。この部分は本当に速いです。数秒以内に、話した言葉がテキストとして表示されることがわかります。何時間も待つ必要も、複雑なセットアップも必要なく、すぐに結果が得られます。テキスト ファイルをクリックし、[字幕ファイルのトランスクリプトをエクスポート] を選択して保存し、ビデオに字幕として追加します。
ビデオ音声をテキストキャプションに変換したい場合、Filmora のモバイルアプリでは AI キャプション機能も提供しています。モバイル デバイス上で 1 分以内にテキスト キャプションを生成できます
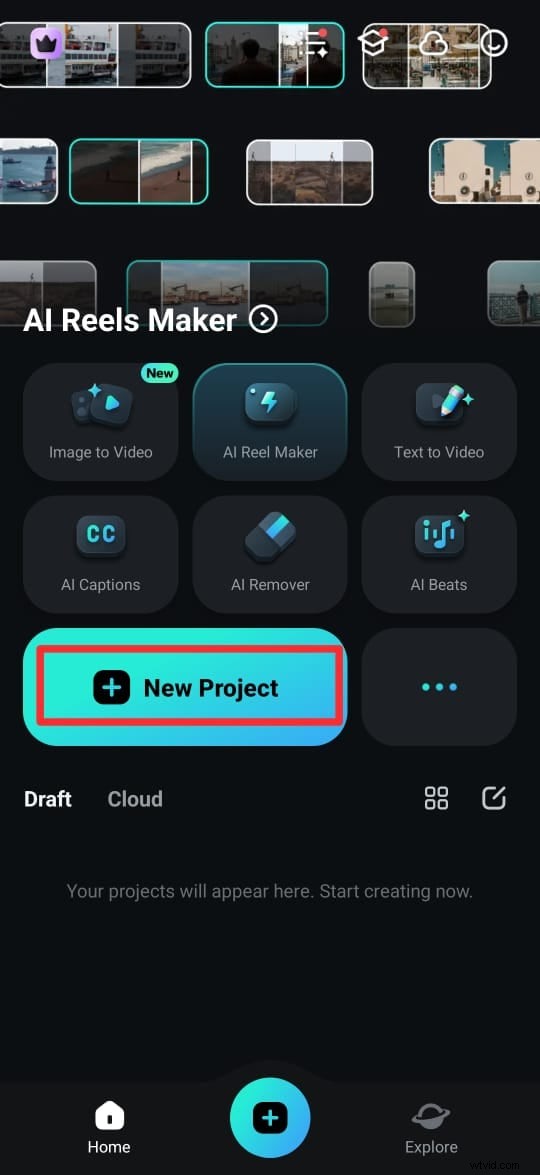
ステップ 1:Google Play ストア (Android) または App Store (iPhone) から Filmora アプリをダウンロードします。公式サイトからも入手できます。インストールしたら、アプリを開いて [新しいプロジェクト] をタップします。
ステップ 2. メディア ライブラリからビデオを選択し、[インポート] をタップしてワークスペースに追加します。

ステップ 3:下部のメニューで、[テキスト] (T アイコンのマーク) をタップし、[AI キャプション] を選択します。
ステップ 4:次の画面で言語を選択し、話者検出をオンにして、[キャプションの追加] をタップしてビデオの音声からテキストを生成します。
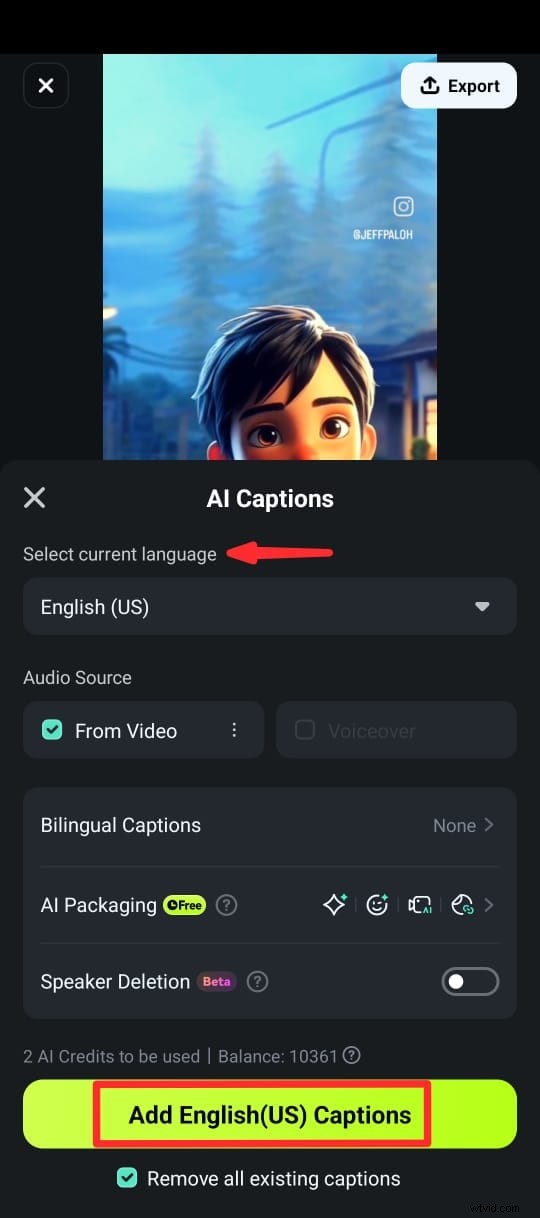
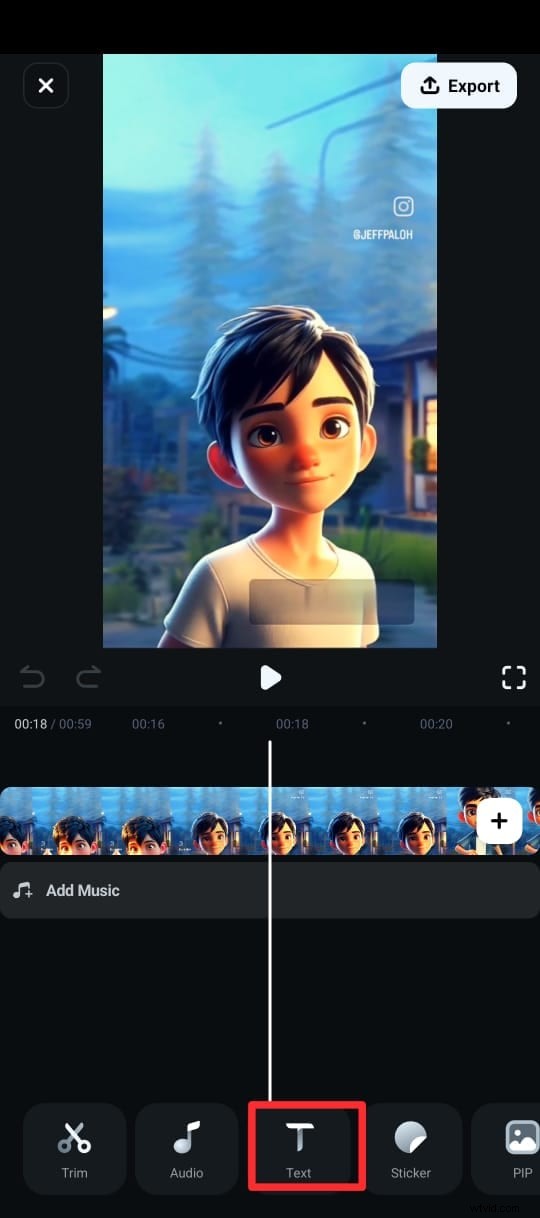
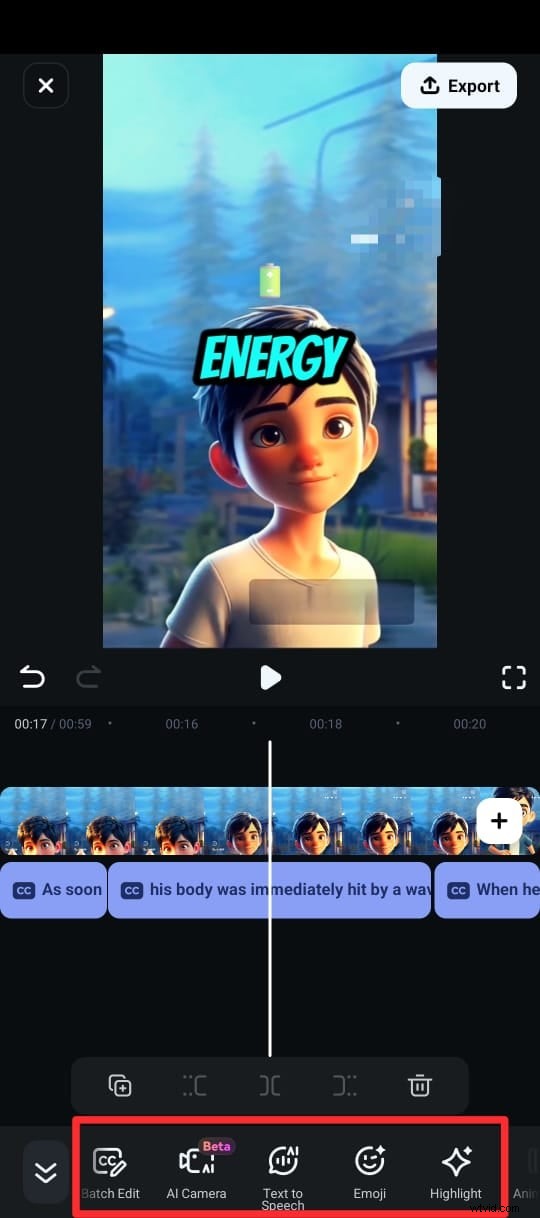
ステップ 5:キャプションが生成されたら、さまざまなテキスト テンプレート、絵文字、フォントを使用してテキストをカスタマイズできます。編集スイートから [スピーチの編集] を選択して、タイムラインのクリップ内のテキストを編集することもできます。
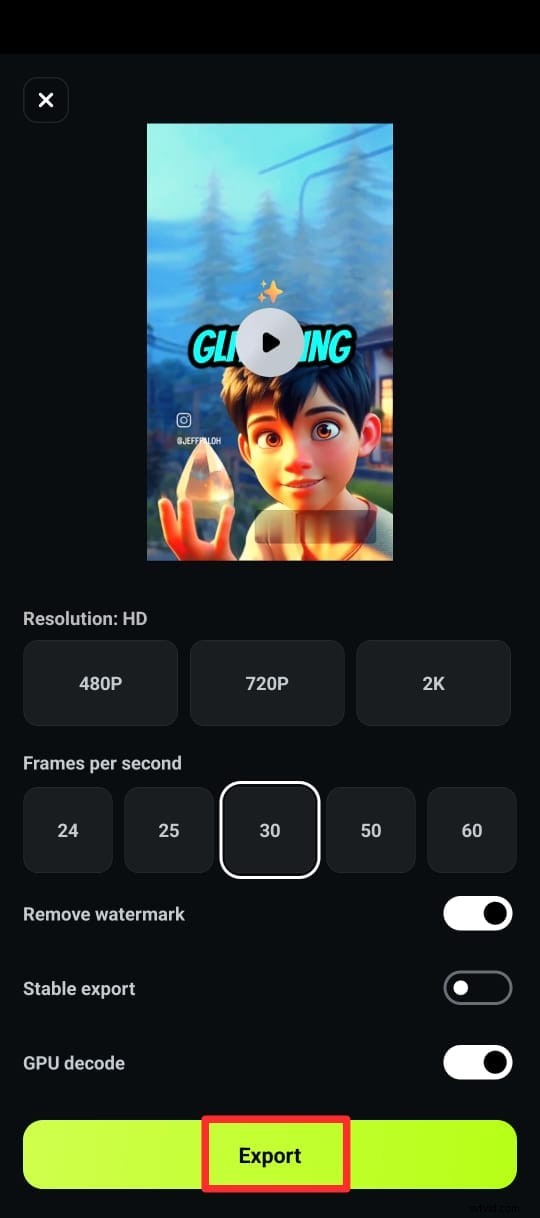
ステップ 6:希望の形式でキャプション付きのビデオをエクスポートします。
パート 5. どのツールが最適ですか?
Hugging Face と Filmora のどちらを選択するかは、特定のニーズと技術的専門知識のレベルによって異なります。各ツールは異なる目的を果たすため、さまざまなシナリオに基づいてどれが最適かを検討してみましょう。
- 高度なカスタマイズと AI を活用した制御が必要な場合は、Hugging Face の音声からテキストへの変換が適しています。モデルのトレーニング、パラメーターの微調整、大規模なデータセットの操作を行う開発者、研究者、専門家に最適です。ただし、コーディングの知識とセットアップに時間が必要なため、初心者や迅速な解決策を探している人にはあまり適していません。
- 一方、技術的なセットアップを必要とせずに、高速で正確な文字起こしツールが必要な場合は、Filmora が最適です。シンプルなワンクリック ソリューションを必要とするコンテンツ クリエイター、学生、専門家向けに設計されています。
- 動画に字幕やキャプションを追加したり、講義を文字に起こしたり、レポート用に音声をテキストに変換したりする場合は、Filmora を使用してください。
- ドメイン固有の音声認識を必要とするニッチな分野で作業している場合、Hugging Face を使用すると、業界固有の用語に基づいてモデルをトレーニングできます。これにより、複雑な専門用語の精度が向上しますが、やはり労力と技術的なノウハウが必要になります。
- 一方、ビデオ コンテンツの文字起こしが主な目的の場合は、音声をテキストにすばやく変換できる Filmora がより便利なオプションであり、YouTuber、ポッドキャスター、ソーシャル メディア クリエイターにとって理想的です。
要約すると、コーディングが好きで、完全な制御とカスタマイズが必要な場合は、huggingface のテキスト読み上げを使用してください。ただし、簡単で即時の文字起こしツールが必要な場合は、Filmora が最適な選択です。自分のワークフローとスキル レベルに最も適したものを選択してください。
結論
音声をテキストに変換するのは複雑である必要はありません。 ハグフェイスのテキスト読み上げ は強力なツールですが、コーディングとセットアップが必要であり、開発者にとっては便利です。ただし、迅速かつ簡単なものが必要な場合は、Filmora が最適な選択肢です。数回クリックするだけで、音声を簡単に書き写すことができます。コーディング不要でストレスもありません。複雑なセットアップに何時間も費やす必要はありません。 Filmora の音声テキスト変換機能を今すぐお試しください。音声を数秒でテキストに変換できます