
Google での音声検索がどれほど楽であるか疑問に思ったことはありませんか?その答えは、話し言葉をリアルタイムでテキストに翻訳する自動音声認識 (ASR) テクノロジーにあります。
基本的な音声テキスト変換ツールは単に単語を書き写すだけですが、高度な ASR システムは人工知能と機械学習を活用して、より高い精度を実現し、多様なアクセントを認識し、背景ノイズをフィルタリングし、文脈上の意味を把握します。そのため、仮想アシスタント、カスタマー サービス ボット、音声検索エンジンにとってこれらは不可欠なものとなっています。
このガイドでは、ASR の仕組みを説明し、一般的な通説の誤りを暴き、Filmora のビデオ編集スイートなどの現実世界での用途を探り、将来の課題と機会について概説します。
この記事について
<オル> 自動音声認識システムとは何ですか、またその仕組みは何ですか?
ASR システムに関する一般的な通説と事実
自動音声認識テクノロジーの使用方法
ASR アプリケーションの課題と今後の展開
パート 1:自動音声認識システムとは何か、またその仕組みは何ですか?

自動音声認識 AI、機械学習、言語モデルを適用して音声信号を分析および解釈することにより、話し言葉を書き言葉に変換します。 Siri や Alexa などの音声アシスタントを強化し、文字起こしサービスを推進し、コールセンター分析をサポートし、リアルタイム翻訳ツールを支えます。
このプロセスは単に聞くだけではありません。 ASR システムが通常どのように動作するかは次のとおりです。
ASR システムはどのように機能しますか?
- 音声はマイクまたはアップロードされた音声ファイルを通じてキャプチャされます。
- 前処理により信号がクリーンになり、ノイズが低減され、明瞭さが高まります。
- 音声は短いフレームに分割され、ピッチ、トーン、リズムなどの特徴が抽出されます。
- 膨大な音声コーパスでトレーニングされた音響モデルは、これらの特徴を音素確率にマッピングします。
- 言語モデルは、文法、一般的なフレーズ、構文に基づいて最も可能性の高い単語シーケンスを予測し、曖昧さを解決します(例:「音声を認識する」と「素敵なビーチを破壊する」の区別)。
- デコード アルゴリズムは音響と言語の証拠を組み合わせて、最終的な文字起こしをミリ秒単位で出力します。
最先端の ASR システムは、ユーザーの修正から学習しながら予測を継続的に改良するディープ ニューラル ネットワークを採用し、精度を確実に向上させます。
パート 2:ASR システムに関する一般的な通説と事実
広く採用されているにもかかわらず、ASR 機能については誤解が根強く残っています。

| 神話 | 事実 |
| ASR システムは 100% 正確です | Google の Speech‑to-Text や OpenAI の Whisper などの主要なモデルでも、背景雑音や特殊なアクセントにより音声を誤って解釈することがあります。特に重要なアプリケーションの場合は、ポストエディットを行うことをお勧めします。 |
| ASR システムは人間と同じように言語を理解します | ASR は、意味的な理解ではなく、統計的なパターン マッチングに依存します。確率モデル (HMM、ディープ ニューラル ネットワーク) を使用して音を単語にマッピングしますが、意味を真に理解することはできません。 |
パート 3:自動音声認識テクノロジーの使用方法
ASR は音声コマンドだけでなく、ワークフローを合理化するために業界ツールに統合されています。以下は、人気のあるビデオ編集プラットフォームである Filmora 内で ASR を使用する実践的なチュートリアルです。
ASR を備えたビデオ編集ソフトウェア – Filmora
Filmora の AI を活用した話者検出機能は、ビデオ内の個別の音声を自動的に識別し、正確なキャプションや字幕を生成します。これにより、編集者の時間が大幅に節約され、アクセシビリティが向上します。

Filmora のモバイル ASR ワークフローの使用:
- 携帯電話で Filmora を開き、新しいプロジェクトを開始します。ビデオをインポートします。
- [テキスト] をタップします。 → AI キャプション .
- 音声言語を指定するか、Filmora に自動検出させて、[キャプションを追加] をクリックします。 。システムは話者を分析し、字幕を生成します。
- テンプレートからキャプション テンプレートを選択します それを目的のキャプションに適用します。
- ドラッグしてキャプションの配置を調整し、ツールバーを使用してテキスト スタイルを編集します。
- 調整するには、[スピーチを編集] をクリックします。 エラーを修正するか音声を複製するには、[音声を更新] をクリックします。 .
デスクトップでは、プロセスはモバイル バージョンを反映していますが、Speech‑to-Text を使用します。 機能:
- Filmora を起動し、新しいプロジェクトを作成します。動画をタイムラインに追加します。
- クリップを右クリックし、音声合成を選択します。 .
- タイトルを選択します 出力形式として選択し、[生成] をクリックします。 .
- 文字に起こしたテキストは、編集可能なキャプションとしてタイムラインに表示されます。
パート 4:ASR アプリケーションの課題と今後の進歩

ASR は多くのタスクを変革しましたが、いくつかの障害が残っています。
- アクセントと方言 :発音、イントネーション、地域のスラングは誤解を招く可能性があります。
- 音質 :背景のノイズ、エコー、重なり合う音により、文字起こしの精度が低下します。
- 同音異義語 :同じように聞こえるが意味が異なる単語(例:「あそこ」、「彼ら」、「彼らは」)は、文脈上の手がかりがないとシステムを混乱させる可能性があります。
これらの課題に対処するには、より広範囲の音声バリエーションを包含するより堅牢な音響モデルを開発し、文脈上の曖昧さをなくすために自然言語処理を統合することが必要です。
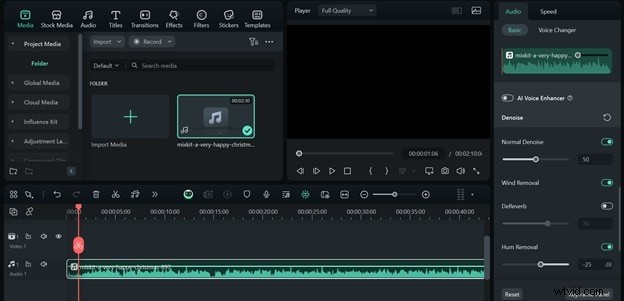
Filmora でオーディオ品質を向上させる
オーディオのアップロードを受け入れる ASR ツールの場合、Filmora はノイズ除去機能を提供します。
<オル> オーディオ クリップをタイムラインにインポートします。
クリップを選択し、エディタパネルを開き、自動正規化を有効にします。 、ノイズを除去します。 、風の除去 、 そしてハム除去 .
ASR パフォーマンスを最適化するために、クリーンなオーディオを MP3 としてエクスポートします。
結論
自動音声認識 単純な文字起こしから洗練された業界ソリューションまで、テクノロジーとの関わり方を再構築しています。 Filmora のようなツールは、ASR がキャプションと音声のクリーンアップを自動化し、生産性とアクセシビリティを向上させる方法を例示しています。
既存の障害にもかかわらず、AI と NLP の継続的な進歩により、近い将来、さらに正確で汎用性の高い音声認識が実現されることが約束されています。

フィルムモーラ
⭐⭐⭐⭐⭐
最高の AI を活用したビデオ編集ソフトウェアおよびアプリ