複数のスピーカーが出演するビデオ (ポッドキャストやインタビューなど) を編集しているとします。キャプションを手動で追加するのは面倒です。話された言葉をすべて聞いて、入力し、同期する必要があります。ビデオエディターがさまざまな音声を自動的に認識し、各話者にキャプションを生成できたらどうでしょうか?そこでPython での話者認識が登場します。 ゲームが変わります。
Python は、その堅牢なライブラリにより、音声ベースのアプリケーションの開発に最適なプログラミング言語です。これらのライブラリは、リアルタイムの音声処理、分析、話者識別のための話者認識モデルの実装と展開に役立ちます。たとえば、Pico Voice Eagle SDK は、AI 主導のアプリケーションに高速かつ正確な話者識別を提供します。
あるいは、音声認識人工知能を統合したビデオ編集プラットフォームもあります。これらは、ビデオの音声をスキャンし、発言者を識別し、同期されたキャプションを生成することによって機能します。
このガイドでは、Python で話者識別を実装する方法を説明します。また、コードを使わずにビデオキャプションを簡単に作成できる最適な代替手段についても見ていきます。

この記事について
<オル>パート 1:オーディオ処理の基礎

すべての音声認識システムは音声処理から始まります。サウンドは連続的なアナログ信号として伝達されますが、コンピューターではデジタル形式が必要です。音声をデータに変換するには、サンプリング レートとオーディオ エンコード技術を使用します。
サンプリング レートは、1 秒あたりのサウンドの録音頻度を定義します。 Python 話者認識の標準 は 16 kHz であり、高精度を保証します。オーディオ ファイルの形式も重要です。WAV、MP3、FLAC が一般的なオプションですが、機械学習タスクには WAV が推奨されます。
Python は、PyAudio や Picovoice Eagle SDK などの特殊なライブラリを使用して、リアルタイムの話者識別を簡素化します。これらのツールを使用すると、開発者は Python でリアルタイム話者識別用のモデルをキャプチャ、分析、トレーニングできます。
パート 2:Picovoice Eagle SDK を使用したリアルタイム話者識別
Picovoice Eagle SDK は、Python での話者認識のための高性能ツールです。 。従来のモデルとは異なり、オーディオをローカルで処理します。この SDK は、Python でのリアルタイム話者識別、特に AI セキュリティ システムやスマート アシスタントにおいて重要です。
さらに、軽量で、Windows、macOS、Linux、Android、iOS、さらには Raspberry Pi を含む複数のプラットフォームでシームレスに動作します。 Pico Voice コンソールにサインアップし、使用状況を認証するためのアクセス キーを取得するだけです。
Python での Pico Voice Eagle SDK のインストールとセットアップ
Python で話者認識のために Picovoice Eagle SDK を統合するには、まずそれをインストールします。これを行う前に、Python 3.6 以降がインストールされていることを確認してください。
ターミナル (Linux/macOS) またはコマンド プロンプト (Windows) を開いて、次のコマンドを実行します。
または
Python がインストールされている場合は、次のように表示されます。
バージョンが 3.6 以降であれば、問題なく使用できます。
まず、必要なライブラリをインストールします。ターミナルで次のコマンドを実行します。
pip install SpeechRecognition pyaudio librosa pvrecorder
Picovoice Eagle SDK の場合は、ダウンロードしてインストールします。
pip install pvporcupine pveagle
Python で Picovoice Eagle SDK を使用してリアルタイム話者識別を実装するためのステップバイステップ ガイド
- ステップ 1:Python をインストールします。 Python の公式 Web サイトで、最新バージョンの Python 3.x.x をダウンロードするオプションを選択します。
- ステップ 2:次に、無料の Picovoice Console アカウントにサインアップし、アクセス キーを取得します。このキーは、Eagle Speaker Recognition SDK を使用するときにリクエストを認証するために必要です。
- ステップ 3:必要な Python パッケージをインストールします。ターミナルで次のコマンドを実行します。
pip install pveagle pvrecorder
これにより、PV Eagle (話者認識用) と PV Recorder (オーディオ キャプチャ用) がインストールされます。
<オル>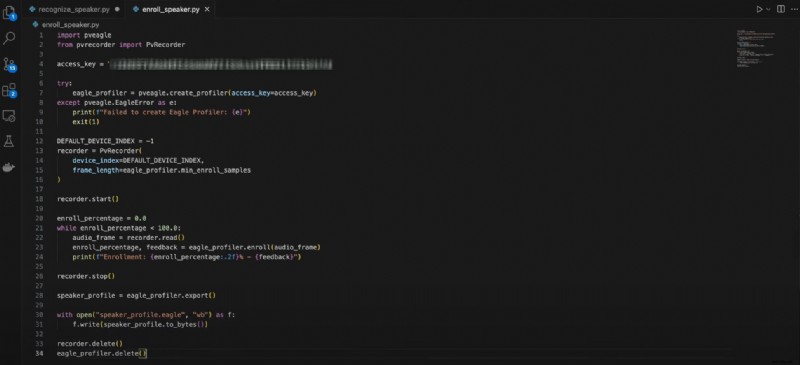
講演者登録用のコードは次のとおりです。
pveagle をインポートするPvRecorder からのインポート PvRecorder
access_key ="YOUR_ACCESS_KEY"
試してみてください:
eagle_profiler =pveagle.create_profiler(access_key=access_key)
pveagle.EagleError を除く e:
print(f"Eagle Profiler の作成に失敗しました:{e}")
出口(1)
DEFAULT_DEVICE_INDEX =-1
レコーダー =PvRecorder(
デバイスインデックス=DEFAULT_DEVICE_INDEX、
Frame_length=eagle_profiler.min_enroll_samples
)
レコーダー.start()
登録率 =0.0
enroll_percentage <100.0 の場合:
audio_frame =レコーダー.read()
enroll_percentage、フィードバック =eagle_profiler.enroll(audio_frame)
print(f"登録:{enroll_percentage:.2f}% - {フィードバック}")
レコーダー.stop()
Speaker_profile =eagle_profiler.export()
open("speaker_profile.eagle", "wb") を f:
f.write(speaker_profile.to_bytes())
レコーダー.削除()
eagle_profiler.delete()
- ステップ 5:端末に移動し、以下のコードを入力して録音します
python3 enroll_speaker.py
スクリプトが実行されたら、マイクに向かって話してみます。あなたの声が登録されたスピーカー プロファイルと一致する場合は、「スピーカーが認識されました!」と表示されます。それ以外の場合は、不明な話者を示します。

- ステップ 6:話者プロファイルの準備ができたので、2 番目のファイルにリアルタイム話者認識用のコードを作成しましょう。これにより、スピーカー プロファイルがロードされ、Pico Voice Eagle SDK を使用してリアルタイムでスピーカーが認識されます。
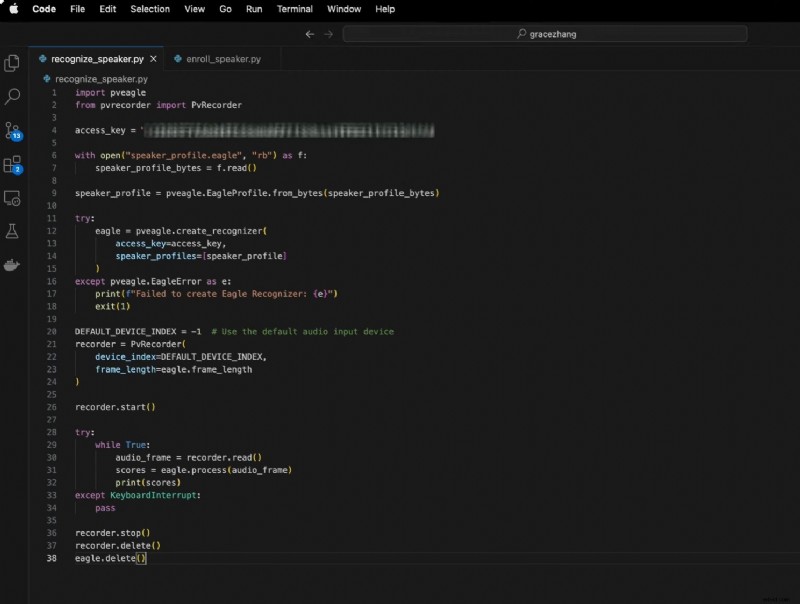
これには以下が含まれます:
<オル>コードは次のとおりです。
輸入pveaglePvRecorder から PvRecorder をインポート
access_key ="YOUR_ACCESS_KEY"
open("speaker_profile.eagle", "rb") を f として使用:
Speaker_profile_bytes =f.read()
Speaker_profile =pveagle.EagleProfile.from_bytes(speaker_profile_bytes)
試してみてください:
eagle =pveagle.create_recognizer(
アクセスキー=アクセスキー、
スピーカー_プロファイル=[スピーカー_プロファイル]
)
pveagle.EagleError を除く e:
print(f"Eagle Recognizer の作成に失敗しました:{e}")
出口(1)
DEFAULT_DEVICE_INDEX =-1 # デフォルトのオーディオ入力デバイスを使用します
レコーダー =PvRecorder(
デバイスインデックス=DEFAULT_DEVICE_INDEX、
フレーム長=イーグル.フレーム長
)
レコーダー.start()
試してみてください:
一方、True:
audio_frame =レコーダー.read()
スコア =eagle.process(audio_frame)
印刷(スコア)
キーボード割り込みを除く:
パス
レコーダー.ストップ()
レコーダー.削除()
eagle.delete()
- ステップ 7:アプリケーションをテストして実行します。
Python3 recognize_speaker.py
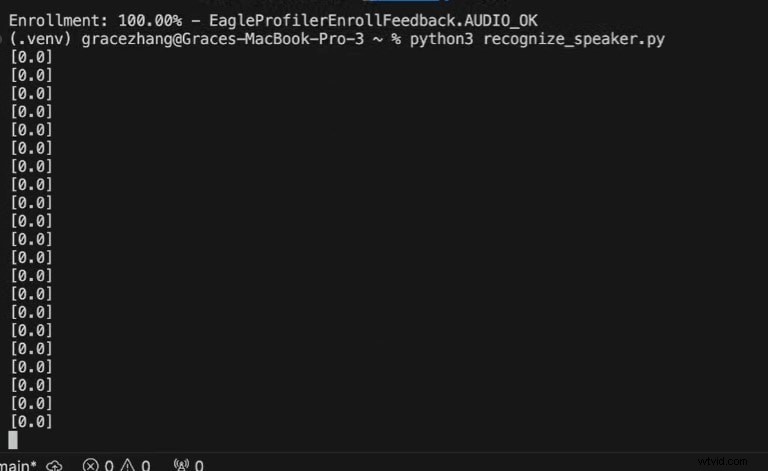
0 =音声が認識されません
1 =音声認識

注:クラウドベースのモデルとは異なり、Picovoice Eagle SDK はデータをローカルで処理します。これにより、結果が迅速に得られ、プライバシーが向上し、インターネットに依存しないことが保証されます。
Python での話者の識別は、プロのプログラマーのみが理解して実行できます。このプロセスを理解するには、ある程度のプログラミングの知識が必要です。
パート 3:話者認識を実行する簡単な方法はありますか?
Python 話者認識システムを構築するには、コーディング スキルと技術的知識が必要です。 Python での識別は強力ですが、プログラマー以外にとっては困難な場合があります。多くのユーザーは、同様の話者および音声認識機能を提供する既製のツールを好みます。これは、コーディングのスキルがなくてもタスクを完了するためのより良い方法です。
そのようなツールの 1 つは、話者認識と音声編集が組み込まれたビデオ エディターである WondershareFilmora です。これにより、ユーザーはコードを 1 行も記述することなく、音声録音を検出、転写、変更できます。
手動のモデルトレーニングが必要な Python 話者認識とは異なり、Filmora の組み込みツールはプロセスを自動化します。 Python や機械学習の知識がなくても、オーディオ ファイルを編集したり強化したりできます。これにより、コンテンツ作成者、マーケティング担当者、ビジネス ユーザーが発言者の識別にアクセスできるようになります。
Filmora のモバイル話者検出および音声編集機能
Filmora には、オーディオ編集と話者認識を簡素化する AI を活用したツールが統合されています。モバイル バージョンでは、ユーザーは話者検出機能と音声編集機能にアクセスできます。
- 話者検出。話者検出は音声を分析し、異なる話者を区別します。手動で音声を聞いてタグ付けするのではなく、AI が誰がいつ話しているのかを識別します。
- 音声編集。音声の編集は面倒な作業ですが、Filmora の音声編集を使用するとプロセスが簡素化されます。これにより、ユーザーは音声録音を変更したり、明瞭度を調整したり、背景ノイズを除去したりすることができます。
外出先で Filmora を使用して音声を認識し、テキストに変換し、編集する方法
Filmora を使用すると、数回クリックするだけで話者を簡単に認識できます。ステップバイステップのガイドは次のとおりです。
- ステップ 1:Filmora をダウンロードし、[新しいプロジェクト] をクリックして、音声付きのビデオをインポートします。
- ステップ 2:テキストを選択して、話された言葉をテキストに変換します。

- ステップ 3:AI キャプションをクリックして音声認識プロセスを開始します
- ステップ 4:[キャプションを追加] を選択する前に、[話者検出] オプションをクリックします
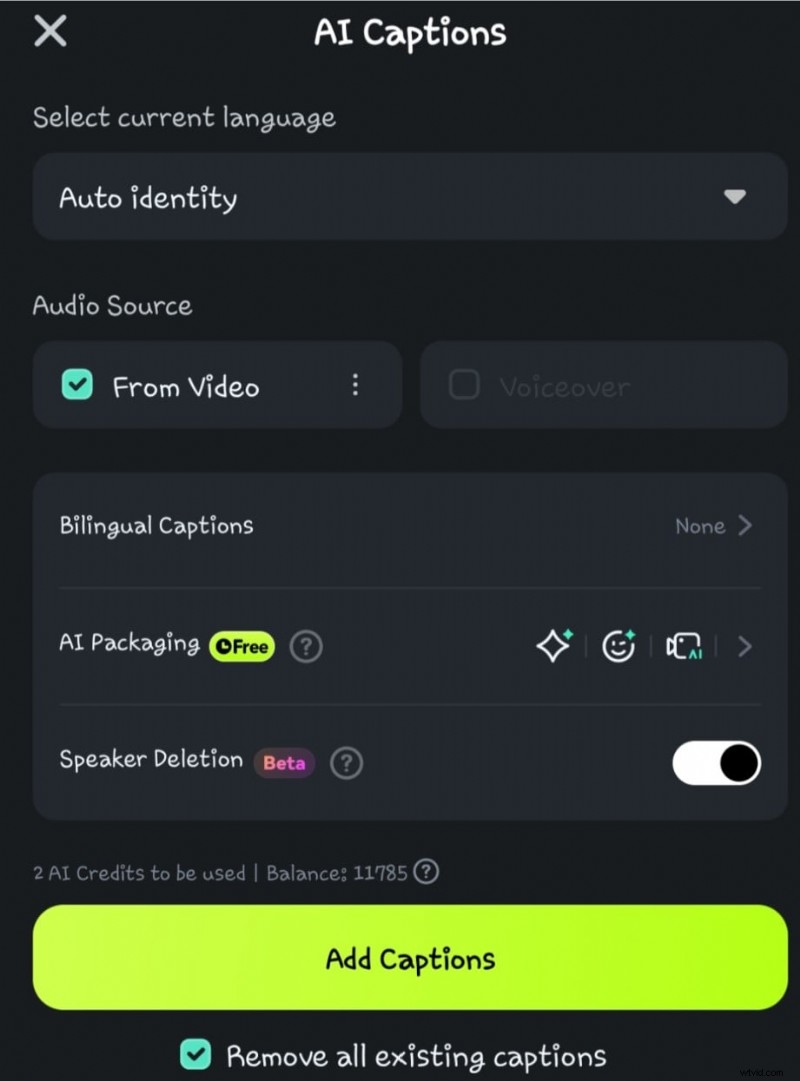
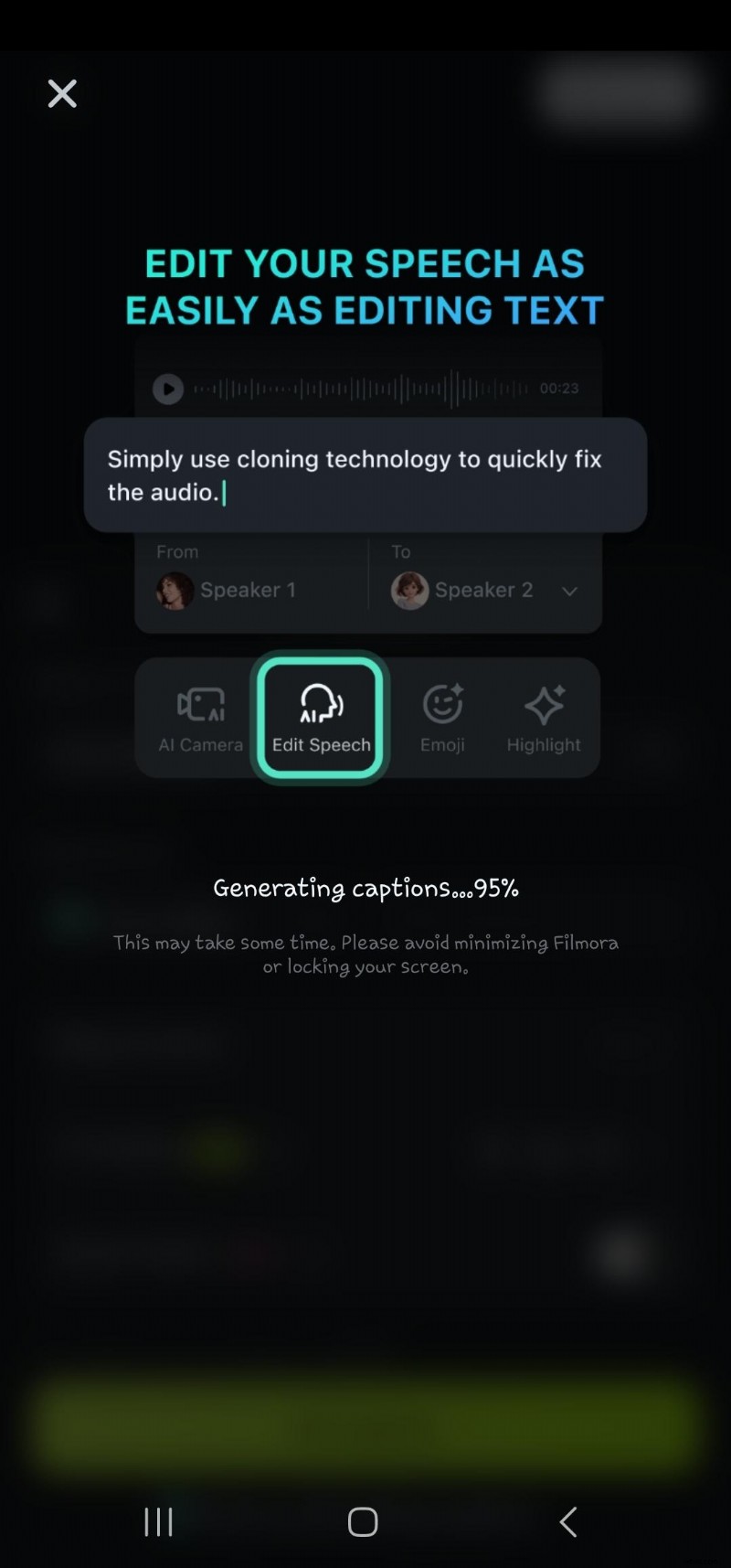
- ステップ 5:AI が音声からテキストへの変換を処理するまで待ちます
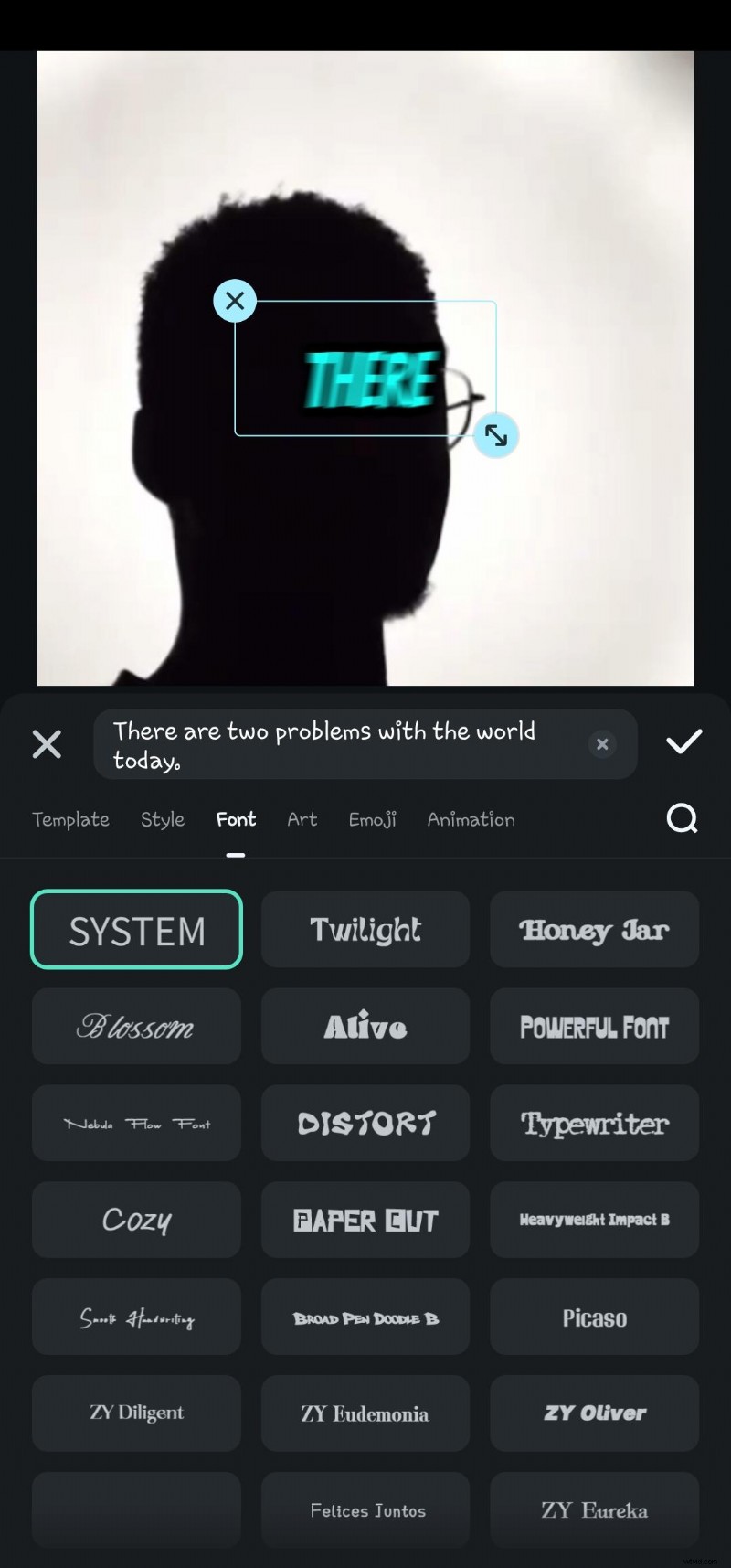
- ステップ 6:タイムラインで生成されたテキストをダブルクリックして、音声編集オプションに移動します。ここでは、アニメーションの追加、テキスト テンプレート、フォント、スタイル、アートなどの変更を行うことができます。
- ステップ 7:ビデオをエクスポートする
注:Python 話者認識によりモデルのトレーニングを完全に制御できることを理解する必要があります。ただし、Filmora は自動化されたアプローチを提供します。 AI 機能により、複雑なプログラミングを必要とせずに、効率的な話者認識が保証されます。
パート 4:話者認識アプリはどこで使用できますか?

Python での話者認識がさまざまな業界を変革していることは疑いありません。このテクノロジーは、ビデオまたはオーディオ ファイル内の音声を識別するための高速かつ信頼性の高い方法を提供します。それはさまざまな業界の基本的な部分になりつつあります。以下は、これらのアプリが適用できる領域です。
<オル>結論
Python は、話者と音声の識別で最も人気のある言語の 1 つです。 SpeechRecognition、PyAudio、Librosa、Pico Voice Eagle SDK などの強力なライブラリを提供します。
これらのツールにより、高精度かつリアルタイムのPython での話者識別が可能になります。 。そのため、開発者、AI 研究者、セキュリティ アプリケーションにとって最適なオプションになります。 Filmora は、プログラミングのスキルを持たない人にとって、より簡単な代替手段を提供します。 Python コーディングを必要とせずに、音声からテキストへの変換、音声編集、話者認識を実現します。
Filmora の AI を活用した自動音声編集および文字起こしツールをお試しください。プロセスが迅速かつフレンドリーになります。

フィルムモーラ
⭐⭐⭐⭐⭐
最高の AI を活用したビデオ編集ソフトウェアおよびアプリ