2026 年 4 月 21 日にリリースされた OpenAI の GPT‑Image2 は、同社の最新のイメージ モデルであり、DALL‑E の後継です。それはパラダイム シフトをもたらします。画像はもはや拡散プロセスによって生成されるのではなく、描画前に考え、計画し、検証する自己回帰システムによって生成されます。その結果、リアルな画像、流暢な多言語テキスト、および市場にある他の AI 画像ジェネレーターとは一線を画す組み込みの推論レイヤーを提供するモデルが誕生しました。
簡単な概要
- 2026 年 5 月 12 日に DALL-E2 および 3 が廃止されたことを受け、GPT‑Image2 は OpenAI の唯一のイメージ モデルになりました。
- その自己回帰アーキテクチャは GPT-4o で使用されるテキスト生成ロジックを反映しており、ピクセルと単語に一貫したパイプラインを提供します。
- テキストの精度は英語で 99% に跳ね上がり、中国語、日本語、韓国語、ヒンディー語、ベンガル語、アラビア語では 90% 以上になりました。
- モデルは、画像を完成させる前に、レイアウトを計画し、ウェブからデータを取得し、結果を自己検証できます。
- アスペクト比の範囲は 3:1 ~ 1:3 で、ネイティブ 16:9 および 9:16 がサポートされます。標準出力は 2K です。 4K は API ベータ版で利用できます。
- この記事では、アーキテクチャの変更、最も影響力のある 5 つの機能、その制限事項、Midjourney、FLUX、Nano Banana2 との比較、InVideo を使用して広範なワークフローに組み込む方法について説明します。
ChatGPT Images2.0 とは何ですか?
GPT‑Image2 は単なる出力を鮮明にするだけではありません。クリエイティブなパートナーのように機能します。このモデルは、プロンプトをそのままピクセルに変換するのではなく、意図を解釈し、構成を計画し、最終的な画像を調整します。 ChatGPT 内および OpenAI API を通じて利用でき、実際のデザイン ワークフローのためのプロダクション グレードのアセット ジェネレーターとして位置付けられています。
GPT‑Image2 がクリエイティブ ワークフローをどのように変革できるか
1.ワンパスで正確なテキストを取得
99% のテキスト精度により、見出し、小見出し、CTA は最初の試行で正しくレンダリングされ、Photoshop でのラウンドトリップやデザイナーによる編集は必要ありません。 DTC ブランドは、それぞれに固有のコピーを含む 10 個の広告バリエーションを生成し、最終的なアセットを直接出荷できます。

2.製品パッケージとラベルのモックアップ
ラベルのブランドコピーはもはや弱点ではありません。 GPT‑Image2 は、中国語、ヒンディー語、日本語、韓国語、アラビア語などの複数の言語で製品名とキャッチフレーズを正確に表記するため、世界的なブランドは初日から自社のコピーに一致するビジュアルを発表できます。

3.あらゆる形式のソーシャル アセット
アスペクト比は、ネイティブ 16:9 と 9:16 を含む 3:1 から 1:3 までになりました。 1 つのプロンプトで、YouTube サムネイル、Instagram ストーリー、LinkedIn バナー、カルーセル スライドをトリミングせずに作成できます。

YouTube のサムネイル

インスタグラムのカバー

カルーセル スライド
4.インフォグラフィックスを簡単に
高密度のレイアウトでも一貫性が保たれます。複数のデータ ポイント、ラベル、ヘッダーは配置した場所に残るため、B2B ブランドはデザイナーに手を渡すことなく、統計量の多いレポートをブランドに沿ったクリーンなインフォグラフィックに変換できます。

5.一貫したキャラクター、環境、イラスト
ゲーム キャラクターからブランド マスコットまで、GPT‑Image2 はシーン間で視覚的な一貫性を維持しながら、ユニークな個性、ファンタジーの世界、未来の都市、歴史的設定を生成できます。



作家、漫画クリエイター、出版社は GPT‑Image2 を使用して物語のビートを視覚化し、視覚的なストーリーテリングを実験できます。


6. UI とコンセプトのモックアップ
GPT‑Image2 は、強力な命令に従って、簡単な画面の説明からクリーンな UI モックアップを生成します。製品チームは、承認のために出力を開発者または関係者に渡すことができます。
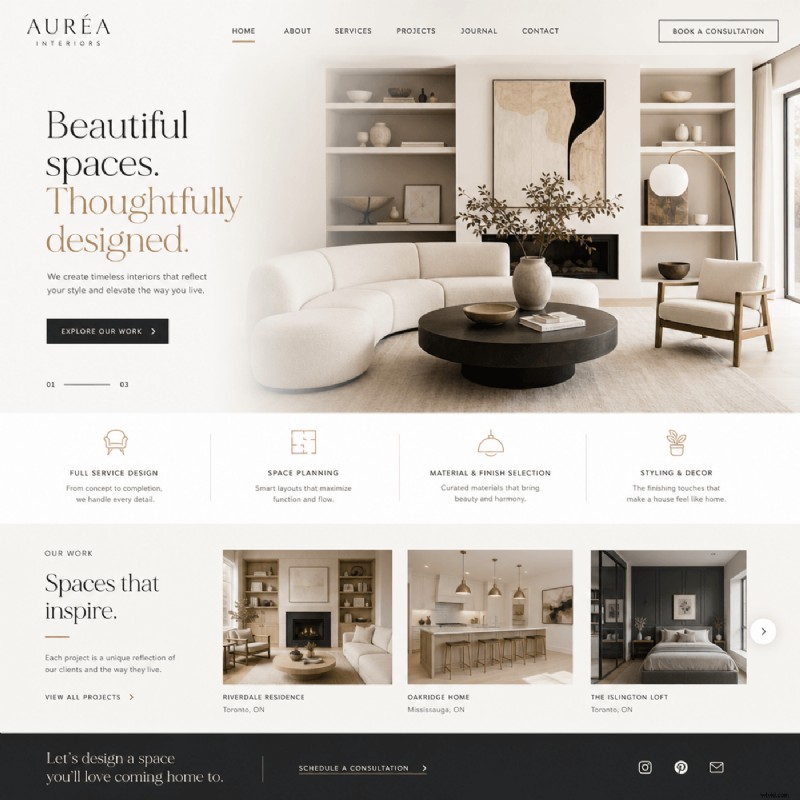
7.社説の表紙とレイアウト
雑誌の表紙や本のレイアウトは、コンセプトを迅速に検討することで恩恵を受けます。 AI が生成した画像は、ユニークな方法でカバー ストーリーに命を吹き込みますが、エディトリアル イラストはページ全体で一貫したビジュアル スタイルを維持します。



GPT‑Image2 がまだ不十分な点
- セッションの繰り越しによりノイズが発生する可能性があります。品質を最適化するためにバッチ間でセッションを再開する
- ポスターの生成を繰り返すと、単一のスタイルに収束する可能性があります。多様性を維持するために、明示的なスタイル指示を使用してプロンプトを変更する
- 物理学、構造精度、技術データ、顔のクローズアップ、曲面や急勾配の表面上のテキストは依然として課題です。アウトプットは人間によるレビューが必要な確固たる出発点として扱う

GPT‑Image2 を際立たせるトップ 5 の機能
1.組み込みの推論
ピクセルを描画する前に、モデルはプロンプトを分析し、構成を計画し、外部データを取得し、OpenAI のテキスト モデルの推論ロジックを反映して自身の出力を検証します。
2. 99% のテキストレンダリング精度
GPT‑Image1.5 は 90 ~ 95% の精度を提供しました。 GPT‑Image2 はラテン文字と CJK スクリプトに対して 99% を保証しており、シングルパス出力をさらに編集することなく公開できます。
3.多言語サポート
中国語、日本語 (漢字とひらがな)、韓国語、ヒンディー語、ベンガル語、アラビア語はすべて正確に表示され、以前のモデルでは対応できなかった市場を開拓します。
4.高解像度と柔軟なアスペクト比
標準出力は2K(2048px)です。 4K は API ベータ版です。アスペクト比には 3:1 ~ 1:3、ネイティブ 16:9/9:16、正方形が含まれるようになり、トリミングの必要がなくなります。
5.強力な指示に従って、構成を制御
空間コマンド (「連続した 3 台の同一のロボット」)、マルチ編集プロンプト、名前によるオブジェクト操作が確実に機能し、密度の高い構成、インフォグラフィック、コミック、雑誌の見開きを一貫性を保つことができます。
GPT‑Image2 対 Midjourney、Nano Banana2、FLUX
| モデル | 最適な目的 | 制限 |
|---|---|---|
| GPT‑画像2 | テキストを多用したビジュアル、多言語テキスト、レイアウトの正確な作業、指示に従い、複数の画像の一貫性 | 物理学と 3D テキストは依然として人間によるレビューが必要です。より小さなエコシステム |
| ミッドジャーニーv8 | 純粋な視覚美 - 編集的、映画的、スタイル主導の作品 | パブリック API はありません。非ラテン語テキストは信頼性が低い |
| ナノバナナ 2 | 大量かつコスト重視のワークフロー | 高密度のテキストや複雑なレイアウトでは精度が低下します |
| FLUX (Black Forest Labs) | セルフホスティング、微調整、オープンウェイト ライセンス | エコシステムが小さく、配布が少ない |